I saw today that Radar raised a Series B for its semantic web application. As I’ve noted in the past, I am a believer in approaching the semantic web top down rather than bottom up, i.e. by inferring structure from domain knowledge rather than requiring all websites to mark up their content in RDF. The user doesn’t care about the semantic web (just as they don’t care about wikis or web 2.0 or tagging), all they care about is that they can more quickly get to the things that they want. The mechanisms that we use to create this better experience should be invisible to the user.
Two companies that are taking this approach are doing it in travel. Travel is a good vertical to start in for three reasons (i) lots of users (ii) well defined universe of data and (iii) easy to monetize.
The first of these is Tripit. Tripit takes travel confirmation emails from multiple sources and creates a master itinerary. As Mike Arrington noted in Techcrunch:
It’s dead simple to use and it keeps you organized – all you have to do is forward confirmation emails to them when you purchase airline tickets, hotel reservations, car rentals, etc. Tripit pulls the relevant information out of the emails and builds an organized itinerary for you. You can send emails in any order, for multiple trips, whatever. It just figures everything out and organizes it.
This is a great example of the semantic web being used to improve a users experience, invisibly. The user neither knows nor cares that Tripit is inferring structure from the emails (e.g. SFO is an airport in San Francisco, the Clift is a hotel in San Francisco, and since your reservation at the Clift starts on the same day as your arrive into SFO, Tripit will offer driving directions automatically from SFO to the Clift etc). All the user knows is that they automagically have a single itinerary compiled and supplemented with other relevant information (e.g. maps, weather etc).
The second is Kango. Kango helps travelers decide where they want to go by crawling 10,000 sites and 18,000,000 reviews and organizing that content semantically. As Erik Schonfeld of Techcrunch notes:
But what’s promising about Kango is the way it slices up search subjectively. Kango is building a semantic search engine focussed narrowly on travel. It parses the language in all of those reviews and guides, and categorizes them by generating tags for them. “You cannot wait for users to add tags, you have to derive them,” says CEO Yen Lee. So hotels that have been reviewed across the Web (on sites like Yahoo Travel, TripAdvisor, or Yelp) with words such as “perfect,” “relaxing,” “couples,” “honeymoon,” or “spa” would rank higher in a search for romantic travel. Hotels associated with the words “kitchen,” “pool,” and “kids,” would rank higher in a search for family trips.
Again, the semantics are being applied in a way that is invisible to users. Users don’t need to know how key words in reviews are mapped to characteristics like “family” or “romantic”. The company uses its domain knowledge to make this transparent to the user.
Expect to see more such semantic web approaches to specific verticals.
Last year I made some predictions about the consumer internet in 2007 and they were at least directionally correct. So let me take a crack at 2008. Regular readers will not be surprised at some of my predictions as they are themes that I’ve been talking about for some time. Later in the week my colleagues will take a crack at predictions for Mobile, Infrastructure and Cleantech.
1. Social Media advertising, Online Video advertising and In-Game advertising start to become scalable.
Social media, online video and games are at early stages of development as advertising vehicles. Even more than the internet at large, a disproportionately small percentage of advertising dollars are being spent on these three media relative to time spent. Some people have even questioned if social media will be a media business at all, or online if video is a good way to monetize.
The slow start is because there are no standards yet in any of these media. If an advertiser wants to buy TV advertising across NBC, CBS, ABC and FOX, they can buy a common unit, the 30 second spot. If she wants to buy print advertising across Time, Fortune, Forbes, Newseek and Businessweek, she could similarly buy a common unit (e.g. a full page ad). But to buy across YouTube, Metacafe and Break, or across Myspace, Facebook and Bebo, or across GTA, Wild Tangent games and Pogo.com games, she needs to buy custom ad units in each property. This makes ad sales look more like business development – she is negotiating not just price, demographics and reach, but also what the actual units are. This is what makes new forms of advertising so hard. All three industries need ad unit standards to be able to scale. Otherwise they will be trapped by demands for customization.
This year, standards will start to emerge in each media. Some candidates for standards include (i) for social media; behavioral targeting, content targeting, demographic targeting or social ads, (ii) for online video; contextual targeting, overlays or pre-roll and (iii) for in game advertising; rich media or product placements. I don’t know which of these candidates will become standards, but I am confident that we will start to see growing support from both advertisers and publishers for the more successful units.
Ad networks will also gain share in each media, helping make the process of both buying and selling advertising easier.
Viewed through this lens, Facebook’s recent Beacon launch and subsequent adjustments are simply early moves towards figuring out what will be the native social media standard.
2. Structured web emerges.
The last couple of years have seen an explosion of user- generated content, across blogs, social networks, social media sites and user reviews. Previously, when most web content was created by editors, there was good structure and metadata around it. As most of the user- generated content has been unstructured, there has been an overall decrease in the level of structure, and hence a decrease in the ease with which people and computers can access and use this data.
Tens of millions of users are now using casual immersive worlds and playing MMOGs. These sites are some of the stickiest on the web, resulting in some of the highest levels of time spent per month online, and indicating that this is becoming a primary form of online communication for some users. Many of these users skew young, and if you believe that demographics is destiny, then you will expect this behavior to spread. The social aspects of these games is key to their popularity
Even more people are playing casual games online. These people often don’t have the ability to commit the time that MMOGs demand. They want to play with their friends, but instead of spending hours online together, they want to do it on their own schedule and in bite sized chunks.
Other key drivers of growth for these products will include innovation in business models (free to play, ad- based and digital goods- based models) and channels (in- browser gaming, mobile, widgets).
Attention economics is an approach to the management of information that treats human attention as a scarce commodity, and applies economic theory to solve various information management problems.
Alex Iskold has a good overview of the attention economy elsewhere at ReadWriteWeb.
By watching user behavior, by inferring intent and importance from the gestures and detritus of actions taken for other purposes, you can sometimes also infer structure about unstructured data. Google does this with its PageRank algorithm, Del.icio.us uses individual bookmarking to build a structured directory to the web, and Xobni maps social networks through analysis of your emailing patterns. Behavioral targeted advertising is based on the assumption that users display their interests through the websites they visit.
Using implicit data to infer structure requires making some assumptions about what each behavior means, but it can be a useful supplement to the other two methods of inferring data. As with inferring structure from domain knowledge, it requires a well defined ontology so that people and things can be mapped against it
Would love to hear more examples of using attention data to infer structure.
As more user generated content floods the web, I’ve been thinking about how to draw more meaning from the content, and the idea that Meaning = Data + Structure. A number of readers commented on my previous post, about user generated structure. They point out that one of the challenges of relying on this approach is finding the right incentives to get users to do the work. I’m inclined to agree. I think user generated structure will be part of the solution, but it probably won’t be the while solution – it won’t be complete enough.
If people won’t do the work, perhaps you can get computers to do it. Is there a way to teach a computer to algorithmically “read” natural language documents (ie web pages), understand them, and apply metadata and structure to those documents? Trying to do this on a web wide basis rapidly gets circular – since this ability is exactly what we need for a computer to comprehend meaning, if it existed then you don’t need the structure in the first place. The structure is our hack to get there!
All is not lost though. In the grand tradition of mathematics and computer science, when faced with a difficult problem, you can usually solve an easier problem, declare victory and go home. In this case, the easier problem is to try to infer structure from unstructured data confined to a single domain. This substantially constrains the complexity of the problem. Alex Iskold has been advocating this approach to the semantic web.
Books, people, recipes, movies are all examples of nouns. The things that we do on the web around these nouns, such as looking up similar books, finding more people who work for the same company, getting more recipes from the same chef and looking up pictures of movie stars, are similar to verbs in everyday language. These are contextual actuals that are based on the understanding of the noun.
What if semantic applications hard-wired understanding and recognition of the nouns and then also hard-wired the verbs that make sense? We are actually well on our way doing just that. Vertical search engines like Spock, Retrevo, ZoomInfo, the page annotating technology from Clear Forrest, Dapper, and the Map+ extension for Firefox are just a few examples of top-down semantic web services.
Take people search as an example. By only worrying about information about people on the internet, people search engines can look for specific attributes of people (e.g. age, gender, location, occupation, schools, etc) and parse semi-structured web pages about people (e.g. social network profiles, people directories, company “about us” pages, press releases, news articles etc) to create structured information about those people. Perhaps more importantly though, it does NOT have to look for attributes that do not apply to people (e.g. capital city, manufacturer, terroir, ingredients, melting point, prime factors etc). By ignoring these attributes and concentrating on only a smaller set, the computational problem is made substantially simpler.
As an example, look at the fairly detailed data (not all of it correct!) available about me on Spock, Rapleaf, Wink and Zoominfo. Zoominfo in particular has done a great job on this, pulling data from 150 different web references to compile an impressively complete summary:
Companies with a lot of user generated content can benefit from inferring structure from the unstructured data supplied by their users. In fact, since they don’t need to build a crawler to index the web, they have a much simpler technical problem to solve than do vertical search engines. They only need to focus on the problems of inferring structure.
Many social media sites focus on a single topic (e.g. Flixster [a Lightspeed portfolio company] on movies, TV.com on TV, iLike on music, Yelp on local businesses, etc) and they can either build or borrow an ontology into which they can map their UGC.
Take the example of movies. A lot of structured data for movies already exists (e.g. actors, directors, plot summaries etc) but even more can be inferred. But by knowing something about movies, you could infer (from textual analysis of reviews) additional elements of structured data such as set location (London, San Francisco, Rwanda) or characteristics (quirky, independent, sad).
In addition to search, inferred structure to data can also be used for discovery. Monitor110 and Clearforest are two companies that are adding structure to news data (specifically, business news data) to unearth competitive business intelligence and investment ideas. By knowing some of the relationships between companies (supplier, competitor etc) and their products, and by analyzing news and blogs, Monitor110 and Clearforest can highlight events that may have a potential impact on a particular company or stock.
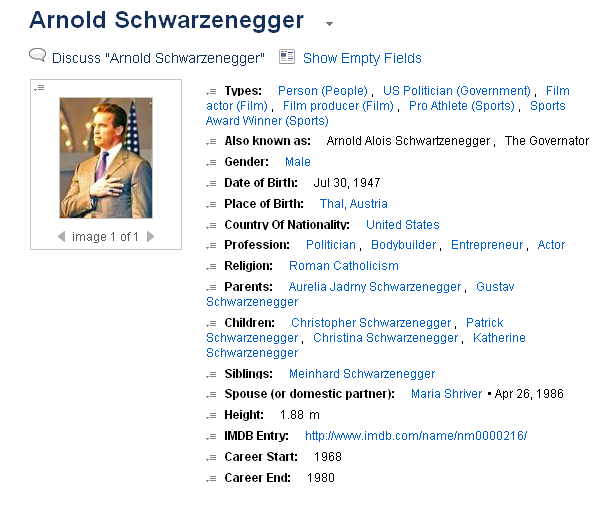
The common criticism leveled against this approach is that it is insufficient to handle the complexity of an interrelated world. Arnold Schwarzenegger for example is a person, a politician, an actor, a producer, an athlete and a sports award winner as the excerpt from Freebase below shows:
Confining an ontology to a single domain, such as movies in the example above, would mean that you are unable to answer questions such as “What Oscar nominated films have starred Governors of California?”.
Teleporting means trying to get to the desired item in a single jump. In this study it almost always involves a keyword search. Orienteering means taking many small steps–and making local, situated decisions–to reach the desired item.
Teleportation requires a universal ontology. With Orienteering, local ontologies with some loose level of cross linking is enough. I suspect that we’re in an orienteering driven search world for the foreseeable future, and that local solutions for specific domains will provide sufficient benefit to flourish. Adaptive Blue and Radar’s Twine are two early examples of products that take this approach. Radar’s CEO,Nova Spivack, talked to Venturebeat recently in some depth on this topic.
My post claiming that Meaning = Data + Structure and follow up post exploring how User Generated Structure is one way that structure can be added to data have generated some great comments from readers. Additionally, a knowledgeable friend, Peter Moore, sent me a long email critique that was so thoughtful that I asked his permission to turn it into a guest post – you’ll find it below.
To rephrase your topic at the risk of going afield, perhaps what one wants is computer assistance in answering questions, including also search queries or browsing operations, that require semantic understanding rather than just filtering by keywords and numerical operators.
For example, if you expect growing US concern about high-carb diets to produce material long-term declines in US consumption of things that make high-carb diets, you might wonder whether that might influence US imports of sugar, and thereby whether it might impact the exchange rate between the Brazilian real and US dollar. You might ask, “What percent of the value of Brazil’s exports to the US are things that go into making high-carb diets? What other products consumed in the US might those Brazilian things go into making instead of high-carb diets? What might drive changes in US consumption of those other things?”
I think that your four approaches are a good way to explore if and how users might add structure sufficient to help us obtain some computer assistance with questions like this, especially where the data being queried is generated by a community of users.
Approach 2: Solicit Structured Data From Users
Perhaps you should have addressed this first, because it seems to me that these efforts by websites to provide a template for their users to fill in is really just a structured database. When users fill in these templates, their entries might go directly into fields in a database. These fields have semantics, so these sites can answer questions with some semantics, but only using the site’s internal knowledge base and only for pre-defined types of questions. The problem is not just the tendency of structure requirements to discourage participation, but more fundamentally, the inability of the application to use information from other sources that didn’t require this same structure, and answering other kinds of questions for which this particular structure is not productive.
Approach 1: Tagging
The first approach will rarely satisfy this desire, however. Tagging might only work for the knowledge base addressed by a single person’s tags, and probably not even that, because many of us don’t tag things consistently even with ourselves. So as you describe in your blog, a question might trip on hypernyms or polynyms, and it certainly won’t understand that a bottle is a kind of container, and so is a can, much less that bottles are typically made of glass or plastic and cans are typically made of metal, so it will miss opportunities to use that kind of semantic understanding to answer questions.
Approach 3: Traditional Approach to the Semantic Web
The third approach is more promising. But unfortunately, it’s not as easy as suggested in your blog by Mike Veytsel, who said:
1) There are already many major hubs of fairly reliable structured data, openly available through APIs. Create a user tagging system that bypasses the ambiguity and redundancy of folksonomies by using only existing, structured data objects as endpoints for tag associations.
2) Use a centralized system to crossmap tags between structured abjects on various data hubs. The issues of systemic bias, false information, and vandalism can be resolved much more easily than in a system like Wikipedia, since one of the major benefits of a tagging system is that, unlike entire articles, tags are atomic in nature, so their accuracy can be measured by weighting. By weightings I mean that, just like in del.icio.us, the more users who’ve tagged a keyword to a site, the more visible and reliable it is.
The problem is that the structured data sources do each use different structures, and mapping between them is very hard. To consider why, let’s first cover some “semantics”:
A “flat list,” such as a list of tags, suffers from all of the issues that you outline in your blog. Many terms may be the same for certain purposes, but without additional information, a computer will not recognize that similarity.
One can provide some of the requisite additional information by organizing a flat list into a “taxonomy,” which organizes entities via “subsumption”: This “is a kind of” that. But even armed with this, a computer will fail to see additional connections between entities, such as this “is a part of” that, or this “causes” that, etc.
One can arm a computer to consider these relations too, transforming a taxonomy into an “ontology,” which uses these additional relations to describe more about a topic. RDF-S is a computer-readable format for describing not only subsumption but also other relations. But it turns out that even when one can describe things with numerous relations, when one tries to move from a small ontology focused on one “domain” to a larger ontology that subsumes more than one “domain,” it becomes very difficult to maintain consistency between items in one area and those in another, albeit related, area. For example, one may author a nice categorization of “products,” including medical treatments by both their mechanisms of action, such as “beta-blocker” or “implantable defibrillator”, and by the medical conditions that each is sold to treat, such as “congestive heart failure” or “cardiac arrest”, in various regulatory jurisdictions. But then one might also want to create a list of companies and organize it by products sold by those companies, such as “Cardiology company” or “Medical device company” or “Cardiology medical device company.” Even with RDF-S, one cannot re-use the ontology of products to organize the ontology of companies, so one will need to create a redundant list of companies, not only creating redundant work but also risking inconsistency, especially if one evolves these ontologies over time. Furthermore, one might also want to create a list of securities, organized by position in capital structure, such as common stock or corporate bond, and by products sold by the issuing companies. So there again one may have another need to re-use the company ontology, which should have already re-used the product ontology. This re-use and nested re-use is a common need.
One can address this need by using Description Logics to create expressions that define some entities in an ontology in terms of other elements in the ontology, such as “Common stock AND issuedBy (Company AND sells (Medical device AND treats Cardiology disease))”. Descriptions Logics are languages that come in many flavors that have been developed in academia for decades. They matter now more than ever, because in 2004, the W3C “recommended” the Web Ontology Language (OWL), which starts with RDF-S and adds Description Logics elements to enable construction of such expressions, all in a machine-readable format that is encoded in XML. But this is no good unless a computer can use the expressions that it reads to infer from them knowledge that was asserted for the elements from which the expressions were built.
That’s what one can do with Description Logics Inference Engines (or “DL Reasoners”), which can use these DL expressions to check consistency of an ontology and infer additional knowledge. Unfortunately, in many circumstances this inference can be computationally challenging, if not intractable, and the field stresses a trade-off between “expressivity” and “efficiency.” That’s why the Description Logics community has developed numerous flavors of languages. If one limits oneself to simple expressions in Description Logics, then one has a chance of answering questions that require some semantic understanding without waiting too long.
I think that long detour is necessary to understand the infrastructure that the (mostly academic and government-sponsored until recently) “semantic web community” has felt it necessary to build to enable curation of ontologies that describe wide-ranging topics, enabling some semantically-aware question assistance from computers outside the domain of a single, narrowly-focused site.
Having established some of this infrastructure, the “semantic web community” is indeed excited about Approach 3, as you suggest in your blog. Among this crowd, the mantra is that the 2004 standardization of OWL as the lingua franca for ontology authoring will enable bottom-up authoring, trading, and reuse of ontologies. This is appealingly democratic and webby, and Swoogle has become a popular place to search for ontologies created by others in the OWL format.
Hopefully, if each content creator can structure his content with ontologies that are reused by others, there may be greater potential for reasoning over the resulting “chimeric” ontology to produce answers that consider semantics. But big challenges remain to this Approach 3, because it remains very difficult to take multiple separate ontologies and merge them into one that is consistent and meaningful for question-answering. The DL Inference Engines can help check consistency of a merged ontology, but the field has recently focused on layering onto these Inference Engines additional tools to support mapping concepts from one ontology to another, identifying homonyms and the like. Two separate groups at Stanford have developed two separate tools for this, called Chimera and PROMPT.
I remain skeptical that this bottom-up aggregation of separate ontologies will produce reasoning robust enough to support the effort involved in merging ontologies. I think that it’s most likely to bear fruit in fairly narrow areas, where one can merge a couple or a few small ontologies to extend one’s reasoning power beyond a single data source to a few data sources. In a way, the merging work may be akin to the next approach, because it asserts a central meaning to broker between the merged ontologies.
Approach 4: Build a Central Authority of Meaning
That may be why some groups continue to try to produce a massive, universal ontology. The Metaweb approach sounds very interesting, partly because it is modest in its reasoning ambitions, so it can pursue a format that does not look like Description Logics and that should feel somewhat familiar to its prospective community of “Wikipedians.” In fact, like most current “semantic web” applications, it relies more on a structure like RDF-S rather than aiming for the broad inference supported by Description Logics. I’m frankly somewhat optimistic about that effort. And I’m curious about Radar Networks’ new service Twine, which started invitation-only beta this week.
But in this area, the Cyc project (www.cyc.com) is also very interesting. It was started by Stanford prof Doug Lenat in the 1980’s, and he moved to Texas on the invitation of the US military to fund a team big enough to build a comprehensive ontology in only . . . about 20 years (so far). In a speech at Google recently, Lenat said that the Cyc team has been “dragged kicking and screaming” into creating over 100 types of relations. That’s in addition to the vast numbers of entities that those relationships connect. They appear to have found difficulty in achieving meaningful inferences without being comprehensive, and difficulty in being comprehensive without this “relation creep.”
But the payoff may be big. Cyc claims to have some success in producing answers that do leverage very general semantics.
Approach 5:
At Clados, we’re using a combination of approaches 3 and 4 to discover imbalances in supply and demand that will produce great investment opportunities. We can discover more imbalances with the aid of some automated organization and cross-referencing across disparate areas via numerous perspectives, and to achieve this, we need a reasonably-consistent ontology, but unlike the Cyc people, we don’t seem to need anything close to a complete one, so we are able to sacrifice completeness in favor of consistency by manually curating everything that goes in, even if some of it comes courtesy of others’ ontologies.
I suppose that this approach may work within a community of user-generated content. A team of curators (with centralized coordination, I’m afraid!) can structure some of the content, and users may be happy to just get some of the inferences that are latent in the unstructured content itself, even if the centrally-coordinated curators will never structure everything.
I’ve been thinking about how the explosion of user generated content that has characterized web 2.0 can be made more useful by the addition of structure, ie meaning = data + structure.
The obvious way that structure can be added to user generated content is by asking users to do it – user generated structure.
There are at least four ways that I can think of to get at user generated structure.
Tagging is the first approach, and its use has been endemic to web 2.0. Sometimes the tagging is limited to the author of the content, and other times any user can add tags to create a folksonomy. Most if not all social media companies employ some form of tagging, including Flickr for photos, Stylehive for fashion and furntiure (Stylehive is a Lightspeed company) and Kongregate for games. Tagging is a great first step, but with well known limitations, as Wikipedia notes:
Folksonomy is frequently criticized because of its lack of terminological control that it seems to be more likely to produce unreliable and inconsistent results. If tags are freely chosen instead of taken from a given vocabulary, synonyms (multiple tags for the same concept), homonymy (same tag used with different meaning), and polysemy (same tag with multiple related meanings) the efficiency of indexing and searching of content is lower.[3] Other reasons for inaccurate or irrelevant tags (also called meta noise) are the lack of stemming (normalization of word inflections) and the heterogeneity of users and contexts.
The second approach is to solicit structured data from users. Examples of sites that do this include wikihow (which breaks down each how to entry into sections such as Introduction, Steps, Tips, Warnings and Things You’ll Need), CitySearch (which asks you for Pros and Cons and for specific ratings on dimensions such as Late Night Dining, Prompt Seating, Service and Suitability for Kids) and Powerreviews (which powers product reviews at partner sites that prompt for Pros, Cons, Best Uses and User Descriptions, including both common responses as check boxes and a freeform text field with autocomplete).
From a UGC perspective, site administrators can force structure by requiring every site contribution to have a parent category, or descriptive tags. The problem is that the more obstacles you put in place before content can be submitted, the less participation you are going to get.
The third approach to user generated data is the traditional approach to the Semantic Web. As Alex Iskold notes in ReadWriteWeb:
The core idea is to create the meta data describing the data, which will enable computers to process the meaning of things. Once computers are equipped with semantics, they will be capable of solving complex semantical optimization problems. For example, as John Markoff describes in his article, a computer will be able to instantly return relevant search results if you tell it to find a vacation on a 3K budget.
In order for computers to be able to solve problems like this one, the information on the web needs to be annotated with descriptions and relationships. Basic examples of semantics consist of categorizing an object and its attributes. For example, books fall into a Books category where each object has attributes such as the author, the number of pages and the publication date.
Ideally, each web site creator would usa an agreed format to mark up the meaning of each statement made on the page, in a similar way that they mark up the presentation of each element of a webpage in HTML. In a subsequent article, Iskold also notes some of the challenges with a bottom up approach to building the Semantic web which can be summarized at a high level as “it’s too complicated” and “no one wants to do the work”.
The fourth approach to user generated structure is to build a central authority of meaning. Metaweb appears to be trying to do this with Freebase, a sort of “Wikipedia for structured data” which describes itself as follows:
Freebase is an open database of the world’s information. It’s built by the community and for the community – free for anyone to query, contribute to, build applications on top of, or integrate into their websites.
Already, Freebase covers millions of topics in hundreds of categories. Drawing from large open data sets like Wikipedia, MusicBrainz, and the SEC archives, it contains structured information on many popular topics, including movies, music, people and locations – all reconciled and freely available via an open API. This information is supplemented by the efforts of a passionate global community of users who are working together to add structured information on everything from philosophy to European railway stations to the chemical properties of common food ingredients.
By structuring the world’s data in this manner, the Freebase community is creating a global resource that will one day allow people and machines everywhere to access information far more easily and quickly than they can today.
There are clearly both advantages and disadvantages with a single authoritative source of user generated structured data; and criticisms similar to those leveled at Wikipedia (potential for systemic bias, false information, vandalism and lack of accountability could cause some data to be unreliable) could be leveled at Freebase. Wikipedia has combated these problems largely successfully through a robust community of Wikipedians – it isn’t clear if Freebase has yet developed a similar protective community.
Conclusion
All four of these approaches offer the opportunity to substantially improve the usefulness of user generated content, and data in general, by adding elements of structure. They are without doubt a meaningful improvement. However, I’m not sure that any of these will offer a universal solution. They all suffer from the same problem that user generated anything suffers from – inertia.
A body at rest needs some external force to put it into motion. Similar, a user needs some motivation to contribute structure. Some people do it out of altruism, others to earn the respect of a community, others for recognition, and yet others for personal gain. Unless these motivations are well understood and either designed into the system, or adjusted for, there is risk that the user generated structure could be either sparse, or unreliable.
I would love to hear reader’s thoughts on these four models of user generated structure, and on other models of user generated structure.
Through Techcrunch, I saw the video “Information R/evolution” embedded below (5minutes, worth watching):
The video’s key message is that when information is stored digitally instead of in a material world, then our assumptions about how to get to information, and how information gets to us, are substantially disrupted, allowing for high quality (and quantity) user generated, organized, curated and disseminated content.
It’s an entertaining video and spot on. However, I think it glosses over one key point about make information truly useful. User generated content, often unstructured, can be very hard to navigate and search through. Adding structure makes the data vastly more meaningful.
Search engines are the best example of how adding structure (a search index) to an unstructured data set (the list of all websites) makes the dataset more useful. Whether that structure is established by link popularity (as Google and all modern search engines do) or by human editors (as Yahoo started out) affects the size and quality of the structure, but even a rudimentary structure built by humans is better than no structure at all.
Social networks are another great example of how adding structure (a social graph) to an unstructured data set (personal home pages) improves the data’s usefulness. There were plenty of successful examples of personal home pages and people directories in the late 90s , including Tripod and AOL’s People Connect, but none of them had the high levels of user engagement that MySpace, Facebook, Bebo and the current generation of social networks have.
One of the key themes of Web 2.0 has been the rise of user generated content. Often this content has been largely unstructured. Unstructured data is hard to navigate by search – you need to rely on the text, and that can be misleading.
Take one of my favorite websites, Yelp, as an example. If I do a search for diabetes near 94111, I get one relevant result (i.e. a doctor) in the top 10 – the rest of the results range from tattoo parlors to ice cream parlors, auto repair to sake stores. All contain the word “diabetes” in a review, some humorously, others incidentally.
This isn’t a one off either; try baseball mitt, TV repair or shotgun. In every case, the search terms show up in the text of the review, which is the best that you can hope for with unstructured data.
Recently I’ve started to become intrigued in companies who are adding structure to unstructured data. There seem to be at least three broad approaches to this problem:
I’m not smart enough to know if this is the semantic web or web 3.0, or even if the labels are meaningful. But I do know that finding ways to add or infer structure from data is going to improve the user experience, and that is always something worth watching for.
I’m going to explore the three broad approaches that I’ve seen in subsequent posts, but would love to hear reader’s thoughts on this topic.
I’ve found this post on the structured web by Alex Iskold to be very helpful in thinking about this topic.
About...
Lightspeed is a leading global venture capital firm with over $2 billion of committed capital under management. Our investment professionals and advisors are located in Silicon Valley, China, India and Israel.
Information set forth on this site should not be construed as investment advice or an offering of any particular investment. Any opinions or views expressed on this site are those of the author and do not necessarily represent the opinion or view of Lightspeed Venture Partners.